Migrating from SFTP to AWS Transfer Service
Overview
This document was written by Myself for a former employer, with contributions from Michael G in Feb 2019. This project was never fully deployed, and it is still to this day, one of my greatest professional disappointments - not being able to get this solution to replace the old solution. The failure was not of a technical nature but a loss of development talent in our project group and a near total refusal to invest in these legacy solutions. I think many companies with a major SFTP type workflow are stuck with something similar to what we had to deal with. It is my hope that companies left with a legacy solution one which worked 20 years ago, but in modern times falls far short on redundancy, security, and even cost. That there are companies, that care enough to invest in a robust solution like the one detailed here, will be able to take this document and build from this proposal.
A project to improve redundancy and security issues related to the current configuration of the upload and processing servers and ssh/sftp access allowed to clients into that server
Original Scope/Idea
Make it so that all upload and import functions are not dependent on a single server in a single AZ.
Move all customer logins to an LDAP/AD solution/get away from local Unix accounts:
Move all data to S3 backend and design an sftp → log in via AD -> S3 directly.
Then on the back-end mount s3 to main and have no direct access to main from outside
What ended up happening
Our original concept for this project was to join AWS’s Transfer for SFTP to AWS’ managed Active Directory in order to send uploads to S3 instead of the main server. What ended up happening through the discovery and Proof of Concept phase of this project is something much different but, in my opinion, an overall better solution. One that scales from dozens of logins to thousands or millions, is reliable, is secure and encrypted, is easy to manage and works for our team, development, and most of all our customers.
AWS Transfer for SFTP does offer its own user management but requires SSH Key authentication only. It does not support password authentication, and it was thought that it would be overly burdensome to have all our thousands of customers understand public/private keys and reimplement every customer to support this change. We want this to be as invisible to the customer experience as possible. This is why it was pertinent to stick with a custom authentication method in order to have success with this project.
We began with an attempt to set up AWS’ Managed Active Directory solution, this was a complete fail for us because you needed more Microsoft Tools, like a Certificate Authority, to provision it properly with SSL.
We then set up an OpenLDAP server, that we ourselves built and would have to manage, a compromise for sure, okay, but not great.
We shifted gears to understand the AWS Transfer for SFTP service AWS offered and even setting up a single test proved to show that we needed far more layers than originally thought. Originally thinking all we needed was some type of directory service plus the Transfer Server. At this point I thought we were doomed, instead, we learned that AWS SFTP needed to connect to AWS API Gateway to connect to AWS Lambda to run code that could verify an account in LDAP to enable access to a single S3 bucket/Directory. What we once thought as 3 new pieces of technology quickly grew to 5 independent pieces.
Lucky to us, AWS had provided a sample CloudFormation template, so we could set up a sample Lambda + API Gateway to see these pieces in action.
From there, the project started to take shape, and we made the discovery that we didn’t need LDAP/AD. It would be much faster and reduce a lot of upkeep cost to store a hash of the login information on DynamoDB and use that to verify accounts.
DynamoDB is a NoSQL solution that allows multi-region, multi-master tables, which we could leverage to make this a much more resilient and smarter application. Users could theoretically connect to the geographically closest SFTP Server and no matter which region their account/S3 bucket lives in have seemingly much faster connection to the service.
Since we had no experience with the API Gateway, all we could do is use the example one and recreate it manually, in order to understand all the pieces of the service. With the help of advanced logging to CloudWatch, we were set up to create our own API Gateway and pull data via the linked Lambda function.
We then built a new Lambda function in python to be able to query DynamoDB and return to the SFTP service the user’s bucket and home directory, along with other data required for the service.
Hooking a new Transfer server to the self-built API Gateway and Lambda function, then working through all the small misunderstandings between the documentation and our own implementation, we were eventually able to get a successful login and upload of data. From there we have continued to optimize the process by modifying the sample CloudFormation template to automatically build our custom Lambda Function, API gateway, S3 buckets, and IAM Roles in each region. At this time, CloudFormation has no hooks to the transfer service so we are unable to automate it using this method.
With the data being available in encrypted S3 buckets, Development can begin to shift how we do imports. Instead of shuffling data around from a manager process to an agent server, the agent service could pull directly from S3 and save a lot of processing and I/O. Furthermore, we think we can hook in additional AWS tools like RedShift and AWS Glue to make powerful Extract, Transform, Load Jobs/techniques and possibly make this whole import workflow completely serverless (!) and much closer to error-free. There’s a lot of work to get there, but the future is not that hard to imagine if we can make sure this new method works with datalink integration and other technical debt items that may inhibit a leap forward like this solution.
 With other teams developing ways for client organizations to have a single account for all products, I believe using DynamoDB as the backend ‘Data-lake’ solution for all this account information would be the perfect use case. The way it can scale in both data housing, replication to multiple regions, and handle high volumes of transactional activity makes it a great candidate and one we would be remiss from not considering.
With other teams developing ways for client organizations to have a single account for all products, I believe using DynamoDB as the backend ‘Data-lake’ solution for all this account information would be the perfect use case. The way it can scale in both data housing, replication to multiple regions, and handle high volumes of transactional activity makes it a great candidate and one we would be remiss from not considering.
New Concept
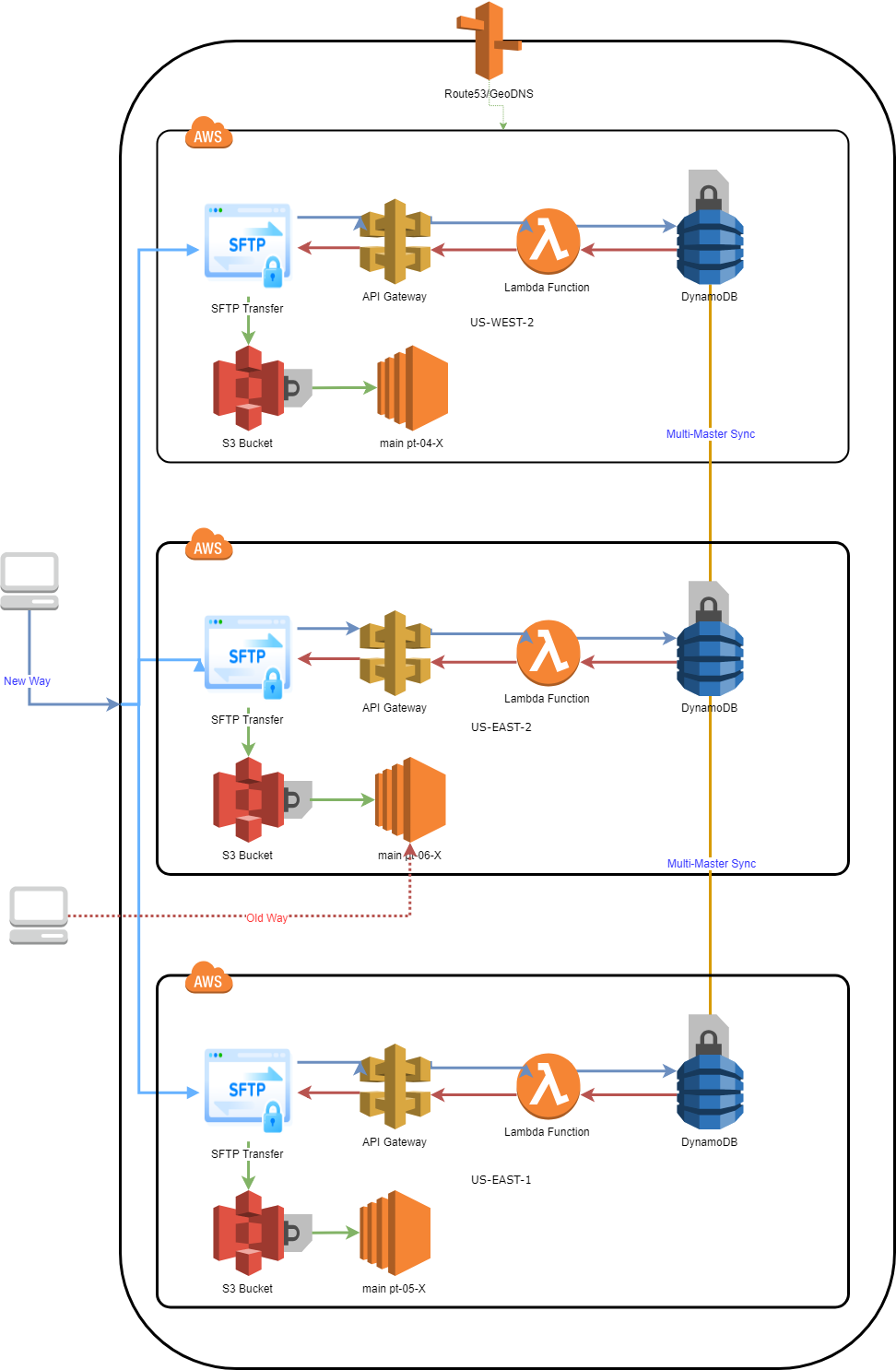
- Every Link between services is done over encrypted traffic be that sftp or https, all data stored is encrypted at rest
Old Concept
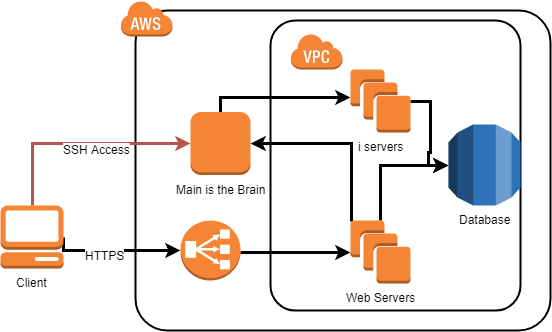
- Main is a Single Point of Failure in the current design.
- Allowing direct SSH Access to one of our most important machines is in our opinion a security and reliability threat to this product.
Images Created With https://www.draw.io/
Cost
Estimated Cost per month for all these new services
| Service | number | price | hour/amount | Total | |
| SFTP | 3 | 0.3 | 720 Hrs | 648 | Seems steep compared directly to 1 server, but in reality, you are getting multiple servers in different AZ's |
| SFTP Transfer | 3 | 0.04 | 200 GB | 24 | |
| S3 + DynamoDB | 3 TB | 80 | https://calculator.s3.amazonaws.com/index.html?key=cloudformation/1e9c79a2-562c-4d46-9977-b6667a3f7455 | ||
| API Gateway | first 333 M | 3.5 | 3.5 | ||
| Lambda | 10 | https://aws.amazon.com/lambda/pricing/ | |||
| Total | 765.5 |
I believe with the new method what we would save in administrative and work time (although I do not have a way to quantify) and the future opportunities this solution provides, far outweigh the slight uptick in cost for this service compared with our traditional method.
Estimated Cost per month for traditional way
If all we did was set up a second main server in a failover auto-scaling group within each cluster to take over should the primary fail, here is the cost structure of that.
| Server | Count | Cost Per | hour / size | Total $ | RI | Total $ | |
| main (m4.Large) | 12 | 0.10 | 720 Hrs | 864 | ~40% | 345.6 | The hope is that without the need to support sftp traffic and zip files to the import servers, we could make the main server smaller and save money |
| EBS Volumes | 6 | 0.1 | 500 GB | 300 | The hope is that we could do away with these large provisioned volumes that we barely use. The volume for 02-1 main uses 150GB and that is the largest one and yet all are this large by default | ||
| Total | 1164 | 818.4 |
As we add more clusters this cost will continue to expand whereas the cost of the new method would stay fairly static and grow only with consumption of resources while adding new volume to the existing traffic
To do
- Have Dev and QA review this solution and understand these changes, give feedback to DevOps for any changes
- Test this solution under “production” levels of use
- Integrate with Provisioning App
- If approved for production, the creation of a migration plan/user outreach/education on why these improvements are necessary and better
Important findings with the new solution
This section is for the lessons, caveats, and findings that were made during testing of this new method that may impact our ability to deploy or things we need to consider as we update datalink or inform our clients.
- The new solution only supports the SFTP protocol. It does not support scp, ssh or anything else other than sftp.
- I think this is especially important for Datalink client, as I know it supports both sftp and scp but not sure what the default is
SCP blocked
$ scp attendance.txt my1sftp@99-uploads.xx.net:
my1sftp@99-uploads.xx.net's password:
Could not chdir to home directory /dev/null: Not a directory
/bin/false: No such file or directory
lost connection
- S3 filesystem does not appear to understand the SETSTAT command, which clients like WinSCP use to preserve timestamps
- If you do not make these changes a warning pops up and looks kind of scary, selecting ‘Skip all’ on error will allow the file to upload as normal \
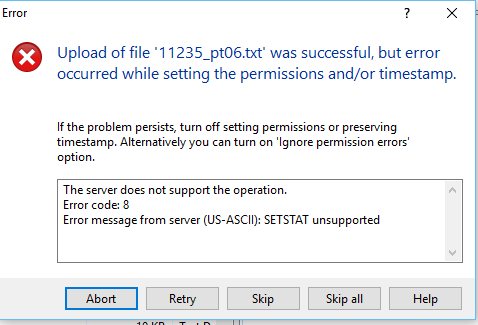
- To disable in WinSCP, Edit Site
- Advanced drop-down arrow, select Transfer Setting Rule
- Unselect “Preserve Timestamps”
- Preset Description - no stat
- Save
- Data stored on S3 are eventually consistent due to data replication
- https://docs.aws.amazon.com/AmazonS3/latest/dev/Introduction.html - Amazon S3 Data Consistency Model
Service Limitations
| Description | Amount | Can be Increased | Source |
| API Gateway | |||
| Throttle limit per region across REST APIs, WebSocket APIs, and WebSocket callback APIs | 10,000/s | Yes | https://docs.aws.amazon.com/apigateway/latest/developerguide/limits.html |
| Regional APIs per account | 600 | No | |
| Edge-Optimized APIs per account | 120 | No | |
| AWS Lambda | |||
| Concurrent executions | 1000 | https://docs.aws.amazon.com/lambda/latest/dg/limits.html | |
| Function memory allocation | 128 MB to 3008 MB, in 64 MB increments. | ||
| Function timeout | 900 Seconds | ||
| S3 | |||
| Maximum object size - Single-part upload | 5GB | https://docs.aws.amazon.com/AmazonS3/latest/dev/qfacts.html | |
| Maximum object size - Multi-part upload | 5TB | ||
| PUT/POST/DELETE | 3500/s | https://docs.aws.amazon.com/AmazonS3/latest/dev/request-rate-perf-considerations.html | |
| GET | 5500/s | ||
| There are no limits to the number of prefixes in a bucket. It is simple to increase your read or write performance exponentially. For example, if you create 10 prefixes in an Amazon S3 bucket to parallelize reads, you could scale your read performance to 55,000 read requests per second. | 55,000/s | key prefix
A logical grouping of the objects in a bucket. The prefix value is similar to a directory name that enables you to store similar data under the same directory in a bucket. |
|
Demonstration
For testing this solution, we created a new org, called ‘Test SFTP 1’
We then have a script to copy the pertinent account data from the MySQL Database to DyanmoDB.
We have another script to run on main to “migrate” the /home/##### Directory to be on the mounted S3 filesystem and a sym-link to make the change invisible to the application.
Showcase of Functionality
sftp upload
$ sftp my1sftp@99-uploads.xx.net
my1sftp@99-uploads.xx.net's password:
Connected to 99-uploads.xx.net.
sftp>
# Demo of Upload/PUT Speed
sftp> put attendance.txt
Uploading attendance.txt to /99-5-uploads/175781/attendance.txt
attendance.txt 100% 5660KB 5.2MB/s 00:01
sftp> put organization\ full.txt
Uploading organization full.txt to /99-5-uploads/175781/organization full.txt
organization full.txt 100% 99KB 1.4MB/s 00:00
sftp> put data_test.txt
Uploading student full.txt to /99-5-uploads/175781/data_test.txt
data_test.txt 100% 28MB 7.7MB/s 00:03
# Demo of Download/GET Speed
sftp> get student\ full.txt
Fetching /99-5-uploads/175781/data_test.txt to data_test.txt
/99-5-uploads/175781/data_test.txt 100% 28MB 5.6MB/s 00:05
# Demonstration of security enhancements - no access to other users' files on the same S3 bucket
sftp> ls
attendance.txt get-pip.py organization full.txt 99-5-import.csv data_test.txt
sftp> ls ../
Couldn't read directory: Permission denied
sftp> exit
Connection reset by 18.224.78.82 port 22
Results
I was then able to go to the website for this org and configure an import using the files uploaded to S3
I was also able to run the import and it appears to have worked without error
Import Success
Test Sftp 1 Import Log
STUDENTS - (IMPORT 3822 AT TEST SFTP 1)
STARTED: 2019-02-08 10:18:33 am EST
COMPLETED: 2019-02-08 10:18:43 am EST
RESULTS:
Import handed to i3.localdomain IMPORTAGENT
2019-02-08 10:18:36 am EST Data import started on host i3
2019-02-08 10:18:36 am EST Data import using database importDB_2000002664
2019-02-08 10:18:36 am EST Extracting data files.
Import Files:
/home/175781/data_test.txt (2019-02-08 15:13:55.00)
Creating Database for import of org 2000002664
2019-02-08 10:18:43 am EST Data import completed.
The Initial functionality test shows that the world continues to spin and to the application the change is invisible. woohoo!
¡MAJOR WIN!
Technical Breakdown of Technologies
I am going to structure each piece of this tech stack from backend to the front, so we can understand and further develop these technologies
The ‘99’ designation in names indicates that this is Dev/Testing
CloudFormation
AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources so that you can spend less time managing those resources and more time focusing on your applications that run in AWS. You create a template that describes all the AWS resources that you want (like Amazon EC2 instances or Amazon RDS DB instances), and AWS CloudFormation takes care of provisioning and configuring those resources for you.
Docs: https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html
Amazon provided a sample CFN template that helped us tremendously with getting the API and Lambda portions setup. Of course, we have adapted thier CFN template to work with our own needs, but without that showing us the way this project would have taken much longer to put together.
Original CFN Template: https://da02pmi3nq7t1.cloudfront.net/aws-transfer-apig-lambda.cfn.yml
One of our Templates: [REDACTED]
The templates that we have written setup S3 buckets, IAM Roles, Lambda Function, and API Gateway for each region.
There are no CFN hooks into AWS Transfer/SFTP service at this time, so we cannot automate this the same way. We also leave DynamoDB out of CFN since the service has to be there before the rest of the stack
After deploying with CFN for the first time, you must do the following
- Get Prod API URL for API Gateway
- Setup Transfer Server with URL from step #1
- Grab the Server ID, ex.: s-36d2dbb2bb8941f59
- Go to lambda and on line 33 set the new serverId
- Still, in Lambda, Add new Trigger with API Gateway to Prod API Gateway. DO NOT REMOVE the one already there
- At this point, all should be configured and testing can begin
DynamoDB
_Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multiregion, multimaster database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second._
| Table | Environment | Info | Primary Key | Secondary Index | Backups | Encryption |
| dydb-99-uploads | Test | Account data for all 99 clusters | orgid | username | PIT us-west-2 only | Default AES-256 |
| dydb-uploads | Production | Account data for all production 01,02,03 clusters | orgid | username | PIT us-west-2 only | Default AES-256 |
Set up a Table
- Create Table
- Set Table Name - dydb-99-uploads
- Primary key - orgid - Number
- Uncheck Default Settings
- Add Secondary Index
- username - String value
- Provisioning: On Demand
- Encryption: Default
- Select Create
Set up Multi-Region, Replication
There can be no data in the tables to setup Streaming Replication, so you need to do this at the beginning right after setup, before you add any items to the table.
- Select Global Tables Tab
- Add region button
- Select Region from menu, Continue
- Repeat if necessary, for another region
The items that do not get replicated are settings related to backups or Tags, we have Point-in-Time Recovery backups of tables enabled in 1 region only, and you have to region hop to apply the same Tags to each table.
We’ve set our tables to replicate with 3 regions: us-west-2, us-east-1, us-east-2
AWS Lambda
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. AWS Lambda executes your code only when needed and scales automatically, from a few requests per day to thousands per second.
Docs: https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
In each region that we have a table configured, we would like to have a lambda function that has Read Only access to the DynamoDB table in the same region.
| Function | Region | Runtime | Role | API Gateway Prod URL | Environment |
| lambda-99-upload-us-west-2 | us-west-2 | python3.7 | 99-upload-us-west-2-LambdaExecutionRole-1FIE08KVUA8WD | [redacted] | Test |
| lambda-99-upload-us-east-2 | us-east-2 | python3.7 | 99-upload-us-east-2-LambdaExecutionRole-1N1T7LDGGZJPY | [redacted] | Test |
Set up a Function
- Function Name: lambda-99-upload-us-west-2
- Runtime: Python 3.7
- Role: 99-upload-us-west-2-LambdaExecutionRole-XXXXXXX
- lambda_function: link to git code
- Memory: Minimum 128 MB
- Timeout: 3 Sec
lambda_function.py
#!/usr/bin/env python
"""
Author: Tom Stewart
About: Lambda function to handle SFTP Login for API Gateway/SFTp Transfer solution
Hooks into DynamoDB where we store SSH224 of user creds
Exec: - AWS Lambda
Notes: -
python3.7
"""
import json
import boto3
from boto3.dynamodb.conditions import Key, Attr
from hashlib import sha224
from base64 import b64encode
def _dyn_lookup_user(event):
dynclient = boto3.resource('dynamodb')
# dydb-uploads = prod, dydb-99-uploads = test
dyntable = dynclient.Table('dydb-99-uploads')
dynresponse = dyntable.query(
IndexName='username-index',
KeyConditionExpression=Key('username').eq(event['username'])
)
for d in dynresponse['Items']:
return d
def _main(event):
# Replace serverID with newly created one after Transfer setup
if event['serverId'] != 's-36d2dbb2bb8941f59':
return {'statusCode':401,
'body': json.dumps({'statusMessage': 'Unauthorixed sftpserver'})
}
# once the test was online, we got thousands of bots trying to login with default creds, so easier to stop it asap then let it go further with processing
bad_name_list = ['admin', 'support', 'root', 'ubuntu', 'tomcat', 'mysql',
'solr', 'postgres', 'test', 'user', 'user1', 'centos',
'ec2_user']
if event['username'] in bad_name_list:
return {'statusCode':401,
'body': json.dumps({'statusMessage': 'Unauthorized user'})
}
authdyn = _dyn_lookup_user(event)
ctx = sha224(event['password'].encode('utf-8'))
phash = b64encode(ctx.digest())
if authdyn is None:
return {'statusCode':404,
'body': json.dumps({'statusMessage': 'Username Not Found'})
}
if event['username'] == authdyn['username'] AND
phash == authdyn['password'].encode('utf-8'):
return {
'statusCode': 200,
'body': json.dumps({'statusMessage': 'Success'}),
'Role': 'arn:aws:iam::024643489849:role/sftp-transfer',
'Policy': '{"Version":"2012-10-17","Statement":[{"Sid":"VisualEditor0","Effect":"Allow","Action":"s3:ListBucket","Resource":"arn:aws:s3:::${transfer:HomeBucket}","Condition":{"StringLike":{"s3:prefix":["${transfer:HomeFolder}/*","${transfer:HomeFolder}"]}}},{"Sid":"VisualEditor1","Effect":"Allow","Action":["s3:ListAllMyBuckets","s3:GetBucketLocation"],"Resource":"*"},{"Sid":"VisualEditor2","Effect":"Allow","Action":["s3:PutObject","s3:GetObject","s3:DeleteObjectVersion","s3:DeleteObject","s3:GetObjectVersion"],"Resource":"arn:aws:s3:::${transfer:HomeDirectory}*"}]}',
'HomeDirectory': authdyn['HomeDirectory'],
}
else:
return {'statusCode':403,
'body': json.dumps({'statusMessage': 'Incorrect Password'})
}
def lambda_handler(event, context):
status = _main(event)
return status
The execution role needs to have IAM access to DynamoDB tables and is executed by API Gateway.
Cloud formation configures all of this and downloads the python code from S3 buckets in the same region. S3 bucket: lambda-pl-upload-${region} Object: pl-upload.zip (prod) pl-upload-99.zip (Test)
Test data for lambda function:
test
{
"serverId": "s-36d2dbb2bb8941f59",
"username": "test99",
"password": "fawrawt45245"
}
API Gateway
_Amazon API Gateway is an AWS service that enables you to create, publish, maintain, monitor, and secure your own [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) and [WebSocket](https://tools.ietf.org/html/rfc6455) APIs at any scale._
Docs: https://docs.aws.amazon.com/apigateway/latest/developerguide/welcome.html
Honestly, the only way I understand this part is to create the sample API Gateway provided by the sample CFN template and recreate it manually to find all the settings and items to configure. That being said I will try my best to outline all the things to setup.
| API Gateway | Region | Lambda Function | Prof URL | Environment |
| api-99-upload-us-west-2 | us-west-2 | lambda-99-upload-us-west-2 | [redacted] | Test |
| api-99-upload-us-east-2 | us-east-2 | lambda-99-upload-us-east-2 | [redacted] | Test |
Set up an API
-
- Create API
-
Protocol REST
-
Name: api-99-upload-us-west-2
-
Endpoint Type: RegionalResources
-
- Select /, Actions Create Resource- Name new resource /servers
- Select /servers, Actions Create Resource- Name new resource /{serverId}
- Select /servers/{serverId}, Actions Create Resource- Name new resource /users
- Select /servers/{serverId}/users, Actions Create Resource- Name new resource /{username}
- Select /servers/{serverId}/users/{username}, Actions Create Resource- Name new resource /{config
- Select /servers/{serverId}/users/{username}/{config, Actions Create Method- Name GET
-
GET Method
- Authorization AWS_IAM
- Request Paths: serverId and username
- HTTP Reguest Headers: Password
- All other settings leave as defaults
-
Integration Request
- Integration Type: Lambda Function
- Unselect Use Lambda Proxy Integration - we will make our own custom mapping in a later step
- Lambda Function: lambda-99-upload-us-west-2
- Unselect Use Lambda Proxy Integration
- Mapping Template
-
Select “When no template matchets the reguest Content-Type header
-
- mapping template
-
application/json
-
Insert this object
Mapping Template
{ "username": "$input.params('username')", "password": "$input.params('Password')", "serverId": "$input.params('serverId')" } -
Save
-
- Integration Type: Lambda Function
-
Integration Response
- No changes to be made here
-
Method Response
-
Before we can do this step we have to create Models for the response data
-
On left-hand bar find Models
-
Create
-
Model Name: 200ResponseModel
200ResponseModel
{"$schema":"http://json-schema.org/draft-04/schema#","title":"200Response","type":"object","properties":{"Policy":{"type":"string"},"Role":{"type":"string"},"HomeDirectory":{"type":"string"}}} -
Repeat to Create a 4XX Response model:
4XXResponseModel
{"$schema":"http://json-schema.org/draft-04/schema#","title":"4xxResponse","type":"object","properties":{"statusMessage":{"type":"string"}}}
-
-
Return to Resources - GET - Method Response
- Add Response
- HTTP Status: 200
- Response Body
- Content type: Application/json
- Models: 200ResponseModel
- Repeat for 401, 403, 404 - Model should be 4XXRespnseModel
-
Actions
- Deploy API
- Deploy to Prod stage
- Any changes made to the api will have to be Deployed to Prod
-
Use Test interface to test that the API + Lambda can communicate.
-
Go back to the Lambda Function and add a new trigger for API Gateway
- Link to api-99-upload-us-west-2
- Prod Stage
- Save Lambda Function
-
Get Prod url for Transfer service
- Back on API Gateway, navigate to Stages
- Select ‘Prod’
- Invoke URL: right click copy URL: ← this is the custom identity provider URL that Transfer needs
- Example: https://redacted.execute-api.us-west-2.amazonaws.com/prod
AWS Transfer for SFTP
_AWS Transfer for SFTP (AWS SFTP) is a fully managed AWS service that enables you to transfer files over Secure File Transfer Protocol (SFTP), into and out of Amazon Simple Storage Service (Amazon S3) storage._
Docs: https://docs.aws.amazon.com/transfer/latest/userguide/what-is-aws-transfer-for-sftp.html
For Test, we have 2 Transfer Servers setup in us-west-2 and us-east-2 regions
| R53 Domain | ServerId | Region | Custom Identity URL | Invocation Role | Environment |
| 99-uploads-us-west-2.xx.net | s-36d2dbb2bb8941f59 | us-west-2 | [redacted] | 99-upload-us-west-2-TransferIdentityProviderRol-IQR1DD02N3LN | Test |
| 99-uploads-us-east-2.xx.net | s-2811a8a8ee9d497f8 | us-east-2 | [redacted] | 99-upload-us-east-2-TransferIdentityProviderRol-E8XY4G85I5CH | Test |
For Prod, we imagine having 1 in each region for a total of 3
Set up a Transfer Server
- Create Server
- Custom hostname:
- None is fine, for Test we have Amazon Route53 DNS alias: 99-upload-us-west-2.pt-xx.net
- Identity Provider: 2. Custom 3. Paste the link from Prod URL of API Gateway
- Invocation role: 4. 99-upload-${region}-TransferidentityProviderRole-XXXXXXX 5. This is created by CFN template and is unique for every Transfer Service
- Logging Role; 6. can be blank, but if you need cloudwatch logs, select sftp-log~~-~~role
- Enter Tags
- Create
The Transfer server takes about 10-15 minutes to set up and become “Online”
You can immediately test with SFTP (so long as you have a set username/password in the DynamoDB table or one can use the very effective Test_transfer python script
test_transfer.py
#!/usr/bin/python
import boto3
client = boto3.client('transfer', 'us-west-2')
response = client.test_identity_provider(
ServerId='s-36d2dbb2bb8941f59',
UserName='test99',
UserPassword='fawrawt45245'
)
print (response)
Route53 / GeoDNS
Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service.
Docs: https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/Welcome.html
| Name | Type | Alias Target | Routing Policy | Region |
| 99-uploads-us-west-2.xx.net | CNAME | s-36d2dbb2bb8941f59.server.transfer.us-west-2.amazonaws.com | us-west-2 | |
| 99-uploads-us-east-2.xx.net | CNAME | s-2811a8a8ee9d497f8.server.transfer.us-east-2.amazonaws.com | us-east-2 | |
| 99-uploads.xx.net. | CNAME / ALIAS | 99-uploads-us-west-2.xx.net. | Latency | us-west-2 |
| 99-uploads.xx.net. | CNAME / ALIAS | 99-uploads-us-east-2.xx.net. | Latency | us-east-2 |
Set Up a GeoDNS Record
Steps to set up a GeoDNS record for one address so that users are provided with the fastest response time based on their location
- Hosted zones, xx.net
- Create Record Set
- Name: 99-uploads.xx.net
- Type: CNAME
- Alias Yes
- Alias target: Select 99-uploads-us-west-2.xx.net.
- Routing Policy: Latency
- Region: us-west-2
- Save Record Set
- Repeat steps with same Name & Settings, but different Alias Target/Region
After discussing GeoDNS with the team at large we determined not to go forward with using this feature and instead just having regional endpoints, this is because we worried about the cost of intra-regional data transfers, something I hadn’t thought of when developing the solution. This is a strong case for over-engineering a project beyond the scope of what’s necessary.
IAM Policies and Roles
CloudFormation generates the Roles and Policies that are generally needed for each service. However, it does not add permissions to the existing sftp-transfer Role for the S3 buckets that is attached via the Lambda function if there is a successful authentication attempt
sftp-transfer: arn:aws:iam::111111111111:role/sftp-transfer
When production is created, we will have to attach the policy arn:aws:iam::024643489849:policy/pl-pt-uploads-sftp-transfer to sftp-transfer in order to allow uploads and downloads from/to the S3 buckets
| Role | Policy | Attached | Buckets |
| arn:aws:iam::111111111111:role/sftp-transfer | arn:aws:iam::111111111111:policy/99-uploads-sftp-transfer | Yes | 99-5-uploads, 99-4-uploads, 99-3-uploads, 99-2-uploads, 99-1-uploads, 99-0-uploads |
| arn:aws:iam::111111111111:policy/uploads-sftp-transfer | No | 01-1-uploads, 01-2-uploads, 01-3-uploads, 02-1-uploads, 02-2-uploads, 03-1-uploads, 03-2-uploads |
The Lambda Function passes the following Role and Policy. The Scope-down policy enables a chroot like action so that the user can only view files in their directory.
Role and Policy
'Role': 'arn:aws:iam::111111111111:role/sftp-transfer',
'Policy': '{"Version":"2012-10-17","Statement":[{"Sid":"VisualEditor0","Effect":"Allow","Action":"s3:ListBucket","Resource":"arn:aws:s3:::${transfer:HomeBucket}","Condition":{"StringLike":{"s3:prefix":["${transfer:HomeFolder}/*","${transfer:HomeFolder}"]}}},{"Sid":"VisualEditor1","Effect":"Allow","Action":["s3:ListAllMyBuckets","s3:GetBucketLocation"],"Resource":"*"},{"Sid":"VisualEditor2","Effect":"Allow","Action":["s3:PutObject","s3:GetObject","s3:DeleteObjectVersion","s3:DeleteObject","s3:GetObjectVersion"],"Resource":"arn:aws:s3:::${transfer:HomeDirectory}*"}]}',
The special Policy cannot be attached with a traditional ARN and thus requires posting the entire JSON object back to the user at login time. https://docs.aws.amazon.com/transfer/latest/userguide/users-policies-scope-down.html
- A Funny aside, as we were starting to evaluate this service, the original Scope Down policy did not have the ${transfer:HomeFolder} variable and thus required the userName to match the Directory in the bucket. The result was that we had a lot of trouble getting the chroot like scope-down policy to apply correctly. We had a mysterious case where with one S3 bucket the chroot worked, but not with a different bucket. Never could figure out the difference. Lucky for us they updated the ability almost overnight while I was experimenting with this.
S3 Buckets
CloudFormation handles all of the bucket creation for the “stacks”. Each bucket is created in the same region as the main server it should be configured to handle data for.
| Bucket | Environment | Region | Encryption | Versioning | Bucket Policy |
| 99-5-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-5-uploads/*"}]} |
| 99-4-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-4-uploads/*"}]} |
| 99-3-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-3-uploads/*"}]} |
| 99-2-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-2-uploads/*"}]} |
| 99-1-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-1-uploads/*"}]} |
| 99-0-uploads | Test | us-west-2 | Enabled | Enabled | {"Version":"2012-10-17","Id":"Policy1548340984399","Statement":[{"Sid":"Stmt1548340975673","Effect":"Allow","Principal":{"AWS":"arn:aws:iam::111111111111:role/sftp-transfer"},"Action":["s3:DeleteObject","s3:DeleteObjectVersion","s3:GetObject","s3:GetObjectVersion","s3:PutObject"],"Resource":"arn:aws:s3:::pl-pt99-0-uploads/*"}]} |
Production S3 buckets are not yet provisioned as we still need to test S3→ Main Solutions
Mounting S3 buckets to a Filesystem
To Mount S3 to the main server, we leveraged an opensource project called s3fs-fuse. It is well regarded through the community and is used in many production systems.
It is in the standard or EPEL repositories for both CentOS 7 and Ubuntu servers.
Set up of S3 Filesystem
It happened on 99-5, on main, i1 and h1, for testing purposes and proof-of-concept. All servers are CentOS 7.x. All actions as root.
Install and Mount S3 filesystem
$ yum update (to 7.6)
$ yum install s3fs-fuse
$ reboot
$ echo [access keys in .aws/credentials in format ID:KEY] > /etc/passwd-s3fs
$ chmod 600 /etc/passwd-s3fs
$ mkdir /sftp
$ s3fs 99-5-uploads /sftp -o passwd_file=/etc/passwd-s3fs
It is important that each upload action (i.e. copy to s3) starts with first locally copying what needs to be uploaded (transparently by s3fs) and then upload it. That means that there must be enough space in the local filesystem to support any file, which will uploaded to s3. The place where the intermediate temporary file is created, can be set with the use_cache directive.
In order to permanently set mount at boot, in case we mount the bucket 99-5-uploads to /sftp as root and temp. files in /tmp/s3-cache, we will add to fstab as follows.
s3fs#99-5-uploads /sftp fuse allow_other,use_cache=/tmp/s3-cache,rw,nosuid,nodev,uid=0,gid=0 0 0
Note: For the tests, we disabled caching (which works only for reading from S3, i.e. GET) , the setting was as : use_cache="" .
Git File Tracking
Since s3fs uses the Fuse sub-system and not a true filesystem, there is no way for inotify to notice changes to s3 and notify the filewatcher.py process.
I’m flagging this as a process that will need to be updated to harness S3 Object Version History features in order to replicate the git features we’ve set up.
When testing on 99-5 server, we had to move the path because the symbolic links caused issues with another internal tool that leverages inotify and local git repo checkins for file tracking (which does work with writing files from the system, just not via sftp/s3)
Size tests
Credit to Michael G, a former colleague of mine who led the performance testing of this solution
The S3 buckets, at the time of writing (Feb. 2019) can support up to 5TB, with files up to 5GB. However, the upload process may happen in two ways: As a single stream for files up to 2GB and multipart, which allows up to 5GB.
The s3fs, by default support multipart upload. However, it chooses the single stream way, if the file is up to 20MB. In case of streaming-like commands (e.g. dd to the s3) the s3fs sees it as less than 20MB and uses single stream, with the limit of 2GB.
For the size tests (and speed of single uploads) we used two types of files, text and binary, and various sizes, 1MB, 5MB, 10MB, 50MB, 100MB, 200MB, 500MB, 1GB, 2GB and 5GB. The purpose of that is not to simulate the actual workload, instead to stress the s3fs and know its limitations. The sizes were chosen to compare up/download times and investigate any speed differentiation in relation to size. The text files are close to real text, i.e. created by arbitrary words of the american-english dictionary, not just letters. This way, any compressing capability will exhibit its merits.
Speed of transfer from outside
- Uploading to the sftp server was found practically the same with uploading via sftp to the master server. The result is expected since the AWS SFTP is nothing more but an instance that reads/writes files from/to S3.
- The upload/download speed was found quite stable and consistent, with about 5MBytes/sec from Pennsylvania, USA and about 3.3MBytes/sec from Brno, Europe.
This measurement, although not exact, is indicative for the expected upload speed from most, if not all, of the customers. - Since the traffic from/to the outside world is more or less limited by the Internet-AWS connections, it is important to have a picture of the actual abilities of the S3 mount. This can be measured with copies in both directions, i.e. uploads and downloads. The test host is i1. All results are saved in an worksheet.
- The tests consisted of repetitions of uploads and dowloads, overwriting or writing new files, repeating same file and whole set twice, with or without cache. Sizes where from 1MB to 5GB.
- The most prevalent conclusion is that the results are highly inconsistent, with speed varying between 5 MB/s and 30 MB/s for upload and 60 MB/s and 200 MB/s for downloads. An exemplar case is the not-cached download of 50MB, which saw speeds between 28 MB/s and 66 MB/s.
- Binary and text files offer similar speeds. In some cases they seemed to be different, but that was widely inconsistent: In other cases the difference was reversed.
- The results show that cache has no effect in writing (i.e. uploading).
- Caching in downloading, though, offers an improvement of 1.8x to 7x comparing to not-cached. The highest benefit is in smaller size files, below 50MB.
- The speed for uploads reaches highest values from the 50MB.
- Download speed changes differently, with highest values for sizes between 5MB and 1GB, but lowering for 2GB and 5GB. That applies to both cached and not cached tests.
| cached | in MB/s | no cache | in MB/s | |
| Size (MB) | Uploads | Downloads | Uploads | Downloads |
| 1 | 4,7 | 61,2 | 4,4 | 13,2 |
| 5 | 12,6 | 160,8 | 12,2 | 22,7 |
| 10 | 14,7 | 188,7 | 16,6 | 31,0 |
| 50 | 24,3 | 134,7 | 26,3 | 45,1 |
| 100 | 20,9 | 102,0 | 24,1 | 54,3 |
| 200 | 27,1 | 86,2 | 25,2 | 47,9 |
| 500 | 26,7 | 188,2 | 23,7 | 48,4 |
| 1000 | 25,0 | 73,6 | 22,7 | 43,8 |
| 2000 | 23,0 | 59,6 | 23,9 | 33,8 |
| 5000 | 23,5 | 59,0 | 22,9 | 31,7 |
Performance tests (stress)
The test consist of multiple reading and writing to S3, mounted to various numbers of systems. The reason is to understand and document the abilities of the S3 as mounted filesystem (s3fs).
Based on the outcome of this test, it can be decided whether agent servers can directly access files on S3.
Describing the setup
The number of agent servers can be up to 10, therefore this is the max number of test hosts.
For better understanding of the scalability of S3 as a file system, the tests run various mixes of reading and writing, from one host, single thread, to ten hosts with 10 threads each.
As target objects (i.e. files) are used the files created in the size tests, only the text version, since there is no usable difference, while those files resemble more to the actual load.
The hosts used are T3.medium, which -according to documentation and various sites - offer a good performance. It is important to note that the AWS instances offer very different throughput in networking. A simple T2.nano can reach 100Mbps, while the chosen t3.medium offers quite stable 250 Mbps, with bursts that reach 10 Gbps.
There is no scalability in the various instance types, only those two numbers, so there is no reason to try different instances.
Preliminary results
These tests help identify the right scaling mix of reads and writes and a basis for comparison. It also helped fine-tune the tests.
Info from: https://cloudonaut.io/ec2-network-performance-cheat-sheet/ , https://aws.amazon.com/ec2/instance-types/, https://aws.amazon.com/ec2/faqs/#Which_instance_types_support_Enhanced_Networking, https://docs.aws.amazon.com/AmazonS3/latest/dev/request-rate-perf-considerations.html
- The time spent reading from the local filesystem is hardly measurable, being consistently under 0.09 sec for 200MB and under 0.004 sec for 10MB. Compared to the actual time spent within s3fs, the local read is negligible. It does not participate in the outcome, since it is lost by rounding the measurements.
- Writing to the local filesystem is quite higher (around 1.5 sec), still much smaller than the s3fs part. However, that part is skipped by sending the read data to /dev/null. This way, the time measured for get actions is cleaned from local filesystem overhead.
- As seen from the results, the effect of threaded multiple copies is more prevalent with bigger size of files. The speed degradation is (averagely) linear (the increase in performance with 200MB files is likely statistical “noise”, possibly some arbitrary improved performance in S3-side or other AWS-infrastructure change).
- The results show that it is very important to run the tests from different hosts, to identify the load: Is it S3-based or host’s network throughput ?
- Also, the results show that there is no need to run all the threaded tests. However, for validity and confirmation, there could be a set limited to 1 up to 8 threads.
| Size (in MB) | |||||||
| Th-count | 1 | 5 | 10 | 50 | 100 | 200 |
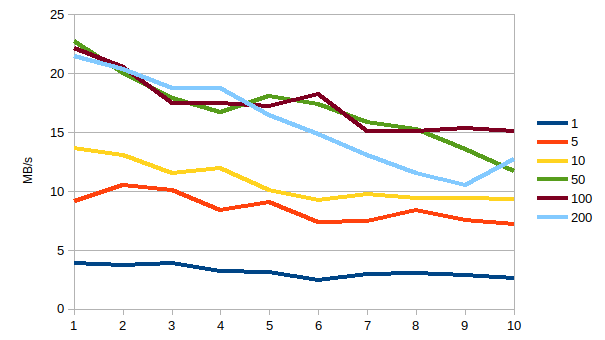
|
| 1 | 3,9 | 9,1 | 13,7 | 22,8 | 22,2 | 21,5 | |
| 2 | 3,7 | 10,5 | 13,0 | 20,0 | 20,5 | 20,4 | |
| 3 | 3,9 | 10,1 | 11,5 | 17,9 | 17,5 | 18,8 | |
| 4 | 3,2 | 8,4 | 12,0 | 16,7 | 17,4 | 18,7 | |
| 5 | 3,1 | 9,0 | 10,1 | 18,1 | 17,2 | 16,5 | |
| 6 | 2,5 | 7,4 | 9,2 | 17,4 | 18,3 | 14,8 | |
| 7 | 3,0 | 7,4 | 9,7 | 15,9 | 15,1 | 13,1 | |
| 8 | 3,0 | 8,4 | 9,4 | 15,3 | 15,1 | 11,5 | |
| 9 | 2,9 | 7,6 | 9,4 | 13,5 | 15,3 | 10,5 | |
| 10 | 2,7 | 7,2 | 9,3 | 11,7 | 15,1 | 12,7 | |
| AVG | 1,74 | 8,51 | 10,73 | 16,92 | 17,37 | 15,84 | |
| MIN | 2,46 | 7,20 | 9,21 | 11,66 | 15,06 | 10,52 | |
| MAX | 3,92 | 10,53 | 13,66 | 22,77 | 22,18 | 21,46 | |
Results
The final tests comprises of the following (code attached as the_tests.sh):
- Threaded copies from the host to the S3 (i.e. PUT or upload)
- Threaded copies to the host from the S3 (i.e. GET or download)
- Threaded copies between the host and the S3 in both directions.
The tests are repeated 30 times (i.e. 30 iterations of the same copy command), on each thread.
Threads run from 1 to 15, i.e. 15 parallel copies from a single host.
The hosts were finally as follows:
- a single t3.medium
- a single m4.xlarge
Unfortunately, this is how far the setup-tests could go. There were continues issues with running the tests. Running 15 repetitions and up to 10 threads, or running the test with only 1MB files in place of each size, it caused no errors. However, when the full-scal setup ran, it never made it to the end. Sometimes, the cp command stuck, while others the whole host faced problems, like an unreachable /var/TEST directory, while in tests. In most cases, the only solution was to reboot.
The configuration of s3fs (i.e. mount options) was the aforementioned for m4.xlarge and t3.medium first run. In t3.medium, another try was done with different configuration (described later), which indeed alleviated the issues.
Tests need to finalise and re-run, at some point.
Caveats
There may be some issues with stability. There were cases that the connection was dropped and, in any action, appears: “Transport endpoint is not connected”.
It may be solved with various limit, timeout and retries parameters. The mixture tried now is: stat_cache_expire=10,retries=9,readwrite_timeout=30,multireq_max=50,connect_timeout=20 .
There are symptoms with using the S3 that might stem from the test or the hosts used. If such symptoms persist, they may critically impede application on production.
The symptoms are explained in current (2019-03-13) results section: The m4.xlarge host did not make it, with the full scale tests.
only put 50 1_15_14 6.12 7.25 3.20 1.80 7.82
cp: error writing '/sftp/uploads/test.50m.bin.1_15_14': No space left on device
cp: failed to extend '/sftp/uploads/test.50m.bin.1_15_14': No space left on device
2.39 7.54 8.01 1.61 5.02
cp: error writing '/sftp/uploads/test.50m.bin.1_15_14': No space left on device
[...]
only put 5 1_15_14 1.08 0.89 1.69 1.28 0.82 0.52 0.85 0.75 0.51 1.71 0.73 cp: cannot create regular file '/sftp/uploads/test.5m.bin.1_15_14': Input/output error 1.05 cp: cannot create regular file '/sftp/uploads/test.5m.bin.1_15_14': Input/output error 2.03 cp: cannot create regular file '/sftp/uploads/test.5m.bin.1_15_14': Input/output error
Source of info:
- https://github.com/s3fs-fuse/s3fs-fuse/wiki/Fuse-Over-Amazon
- https://code.google.com/archive/p/s3fs/issues/314
- https://github.com/s3fs-fuse/s3fs-fuse/issues/254
- https://github.com/s3fs-fuse/s3fs-fuse/issues/506#issuecomment-454331760
- https://github.com/s3fs-fuse/s3fs-fuse/issues/340
- https://github.com/s3fs-fuse/s3fs-fuse/issues/152#issuecomment-278894805
- https://github.com/s3fs-fuse/s3fs-fuse/issues/748